

After the release of our boilerplate projects over on GitHub, one of the main discussions that I’ve noticed taking place and had with others is around the mapping of data models between layers. Now, this conversation hasn’t just occurred around our boilerplates – I’ve noticed that it is one that often comes up when talking about Clean Architecture or Android apps in general. And to be honest, it can be sometimes hard to know what the right approach is – mainly due to their being some form of trade-off being made. Because of this, I wanted to take a look at some of the advantages and disadvantages of mapping models when it comes to your team and project.
Wait, what do you mean by mapping models?
In applications it will often be common to have some form of data model that is fetched from one source and passed through layers of the application, finally to reach its destination of use. In some cases, developers will decide to map these instances to different representations of the data model so that the instance is not so tightly coupled to the whole application. Sometimes the models’ data will be exactly the same, but in a lot of cases, a layers model representation will contain data that is specific to that layer (such as a selected state within a UI model).
Now, there’s a couple of different situations in which you may be mapping your data models. For example, Clean Architecture states it as part of its design in order to allow a clear separation of concerns. The thing is clean architecture provides kinda of a complete solution to architect your application. Whereas other architectural approaches (or even just designs) such as MVP, MVI are more of a detail when used in clean architecture. But if you’re not using clean architecture and just something like one of these patterns as the structure for your project, then do you still need to map your models? If all of my models are within the same module, why should I bother mapping my models? In this post, I want to take a quick look at these different situations to try and assist in some way with making these decisions within applications.
Data models in your projects
The first thing to note is that the mapping of models in your applications really does depend on how the project is structured and the kind of project you are working on – this is the same for any architectural decision that you may be thinking about in your project. For example, imagine an incredibly simple app that has no database and no network requests – a simple app that just shows a list of some hardcoded information. Now, I know these apps might not be something you commonly work on in your day-to-day – but for example’s sake this would maybe look something like this:
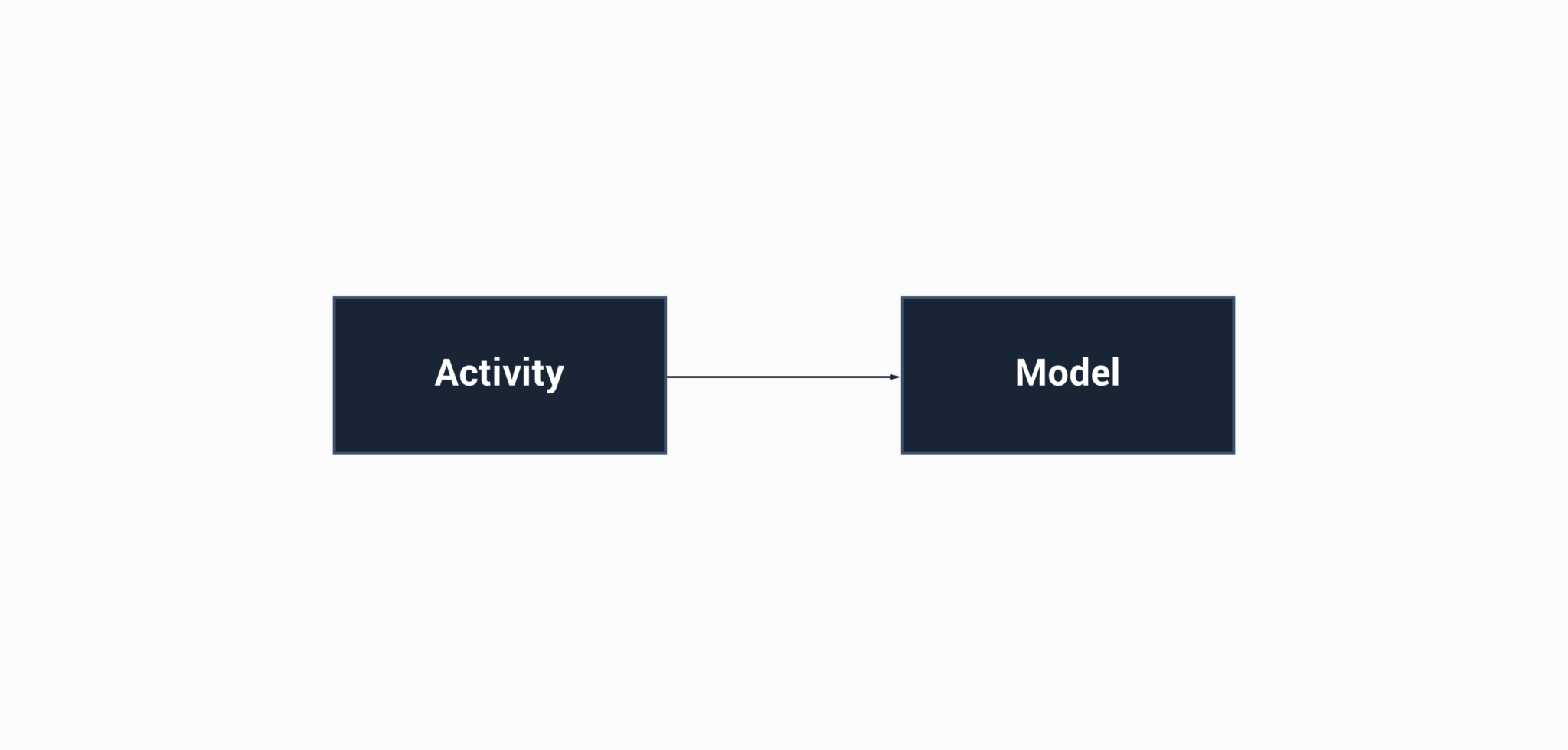
Well, that is a pretty application, isn’t it! We have a single data model in our app that is used directly by the UI. Because this data is hardcoded into the application, we’re never going to place detail into that model that the UI doesn’t need – simply because it is already the representation of our UI. So we have hardcoded UI models in this (this may not be the right solution here but let’s just go with it for now). Unless we wanted to add some form of data layer to our application, it doesn’t quite make sense to map between data models here.
But let’s say things in our app have changed a little – we now fetch these data models from the API and they are no longer hardcoded within our app. This would now look a little like this:
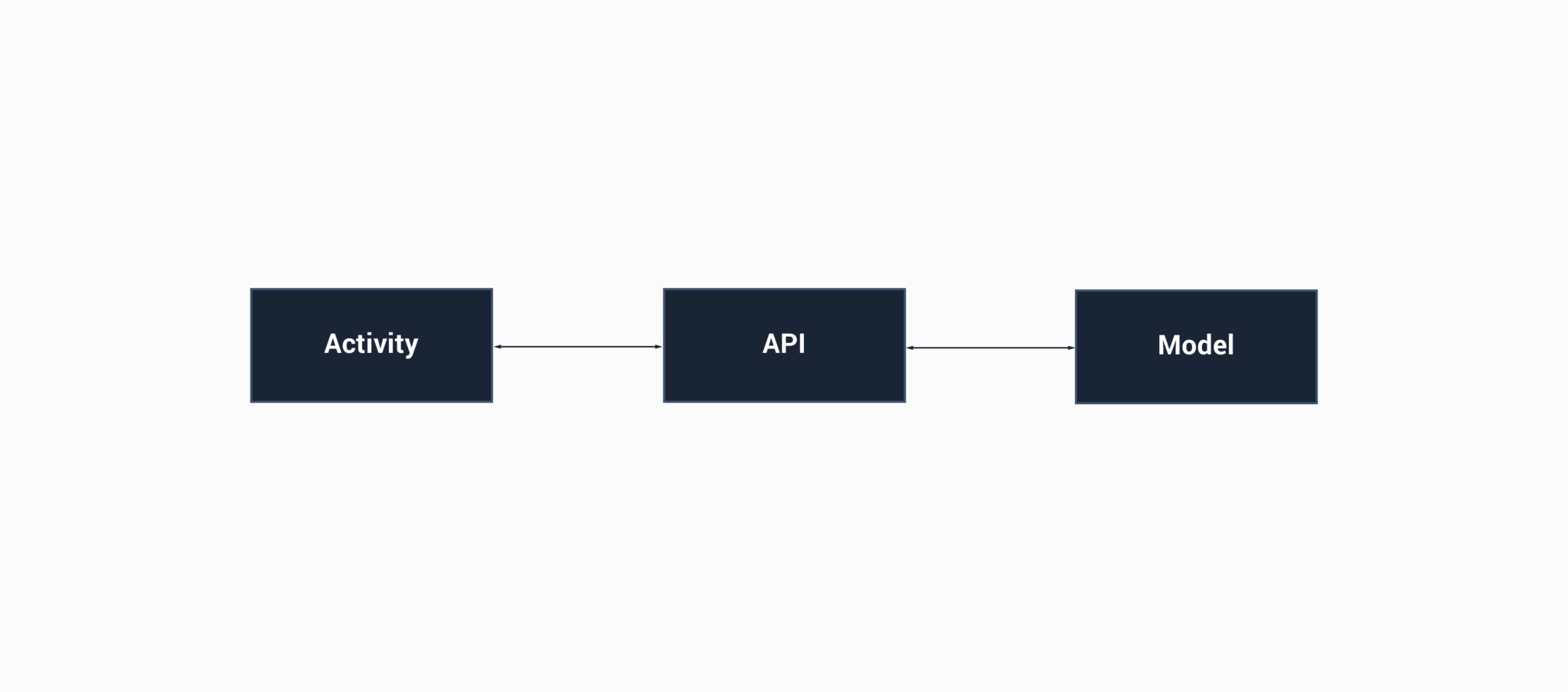
OK cool – so now our app communicates with the API, grabs a model and returns it to us to use in our activity (I’ve excluded complexities here, let’s imagine the API class contains the interfaces and repositories for handling data communication). This looks all good, right? Although, I forgot to point out a few things to do with our model:
– The naming of fields returned by our API is using underscores instead of camel casing, so we need to do things like:
@SerializedName("duration_millis")
var durationMillis: IntThis means we need to include an import to use this annotation, most likely one that our UI doesn’t care about. Our UI model shouldn’t even care about this detail – we could argue that alone this isn’t so bad, if our model is small and never grows then it might not be an issue. but here we break the line of responsibilities and make way for potential bloat in the future.
To build on this further, let’s imagine the following changes are being made to our application:
– We’ve now added a new activity which we need to pass our model to – so we’ve had to make the class parcelable. This means that our model now contains a reference to the Android framework, this is the same model which fetches data from the API. Again, in some opinions, this may not be an issue but we are breaking the line of responsibilities.
– Finally, in our app we can now long press on one of these items, so we’ve had to add a new field to our model to keep track of whether or not the model is selected. So now our model which we use to represent the data retrieved from the network is also containing data which is specific to the view representation of this model. If we were to go ahead and add some view-specific logic here and more view-specific fields, we are going to begin bloating our model and getting into a state of un-maintainability.
You can see now that this single model we have, that is meant to be representing the API data in our application is suddenly becoming populated with properties outside of its concern. Any changes that we make to this model effect all of its uses in our application – there are UI properties that the API response shouldn’t know about and in some cases, it is possible there may be data that the UI doesn’t care about.
OK so let’s say for now we’re not going to change anything – we have mixed opinions on our team so we’re going to move forward with how we are. But wait, now our requirements have changed and we’re going to go ahead an cache our objects in our Database. We’ve added a data manager class too just to separate these out a bit:
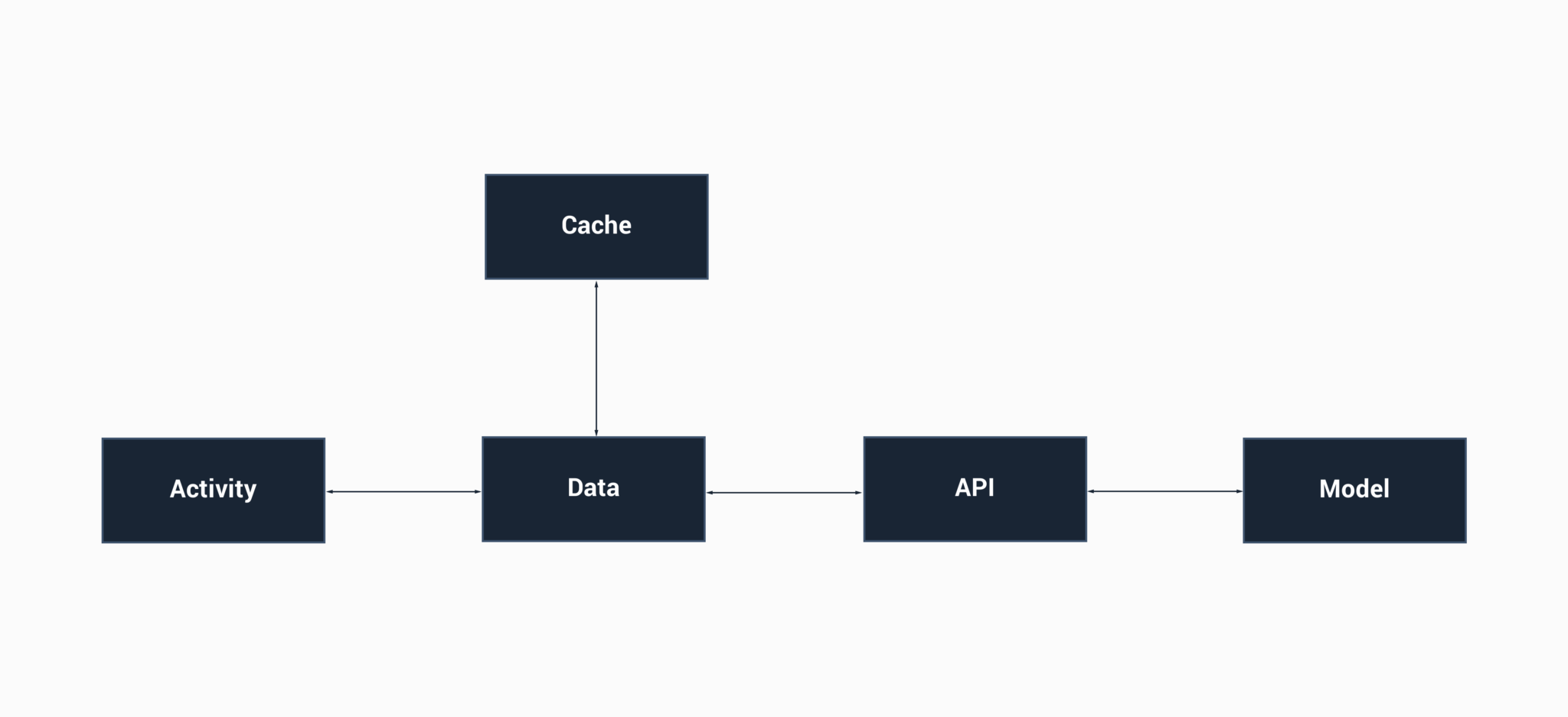
So now we’ve got this in place, and we’re still just using the one model. There are a couple of issues I can think of here to build on top of the ones already mentioned above:
– It is likely that our model is going to have some data which may be only cache-relevant. For example, say if we want to store a last-selected-date field to keep track of the top N selected models are for whatever feature. Our UI doesn’t care about this details and our API doesn’t care about this detail, we would use this field when fetching the top N models, so the caching layer will only ever care about this. This is again contributing to the situation where the line of responsibility becomes broken and adds to a bloating model.
– Similar to remote model annotations, our model is likely going to have some annotations that are cache-relevant. Maybe you’re using Room, you’ll need to use @Entity annotations (and probably others too), this again adds to your models’ structure and results in many responsibilities
There are likely other issues, but I hope by now you can see the point I’m trying to get across. In one of our apps, there is a Profile model that had been there since the beginning – this model was huge. It was cached, it was fetched from the API and it was shown in the UI – the model contained a lot of different annotations, android framework code and UI logic. Altering this model was confusing to work with and opened the way for things to easily be broken.
Now, one way to get around this kind of things is to map your models to other representations. This can be done in a few different ways – maybe you have an API representation and a UI representation, again it is whatever fits your project. In my opinion, it is best to separate out the responsibilities per layer of your application – meaning we would have one for the API response, one for the Cache and then one to be used with the UI.
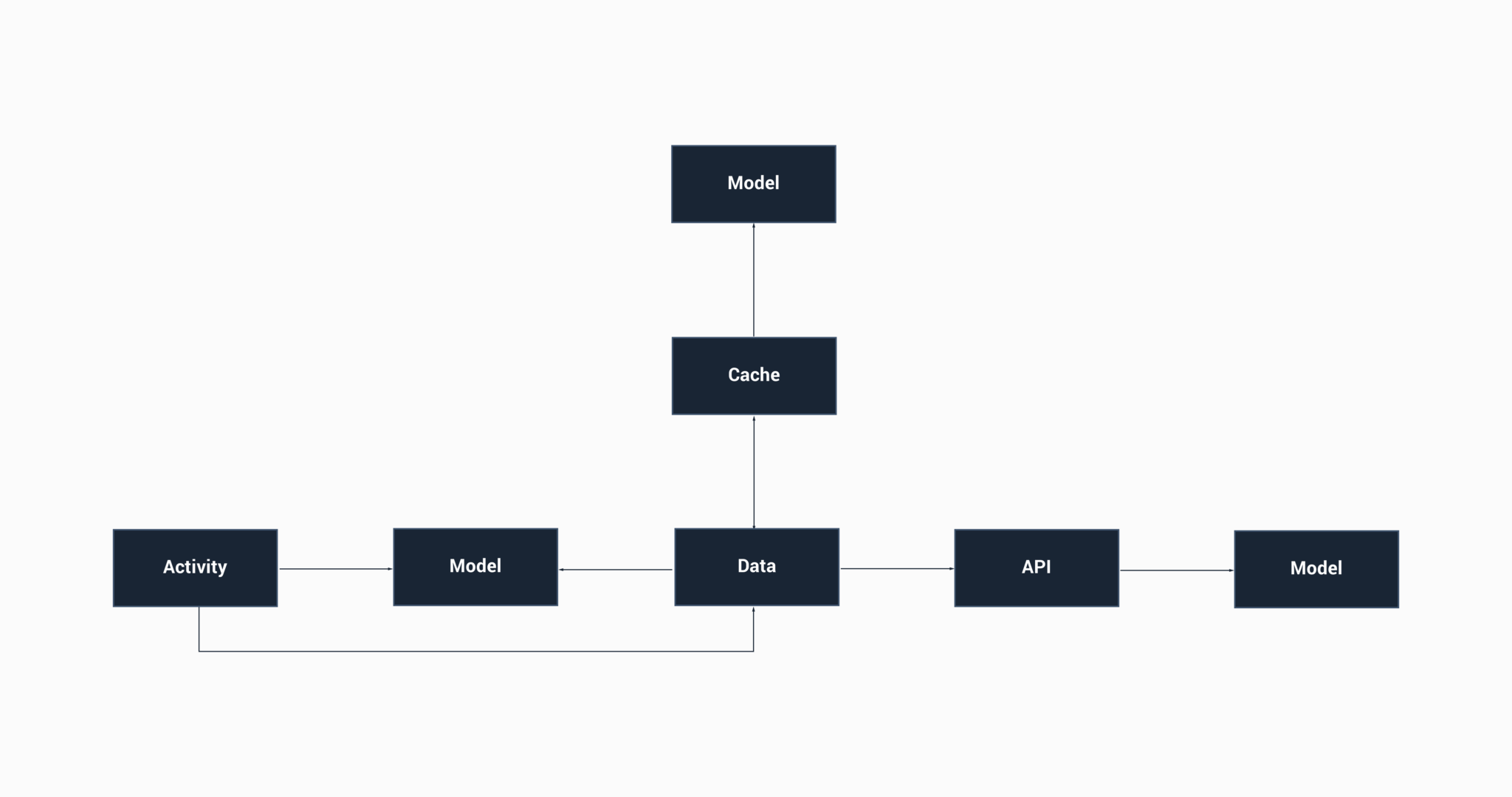
Again, in my opinion, this allows us to have a clear separation of responsibilities. Looking at the diagram above:
– Our model for the API response represents the data that we get back from the API in its pure form. It will always remain android framework free, bloat free (hopefully) and altering this model will never break any expected behaviour in our application (if we alter stuff that is required, our app won’t compile anyway)
– The model used for caching represents the data that we have stored locally in our application. This will in most cases remain android framework free, won’t contain any UI related logic code and gives us space to store data around these objects that may not necessarily be required by our UI.
– Finally, we have a data model to represent the state of our UI. This model may contain references to the Android framework if required (parcelable?), can contain UI logic that is specific to this model and will never break anything in layers outside of our UI.
The mapping here isn’t too excessive. Well, it’s manageable for small applications, but when we have a large application we may become swamped with mapper classes to map between our different instances – we’ll come more onto this later. But for now, I wanted to take a quick look at clean architecture (these conversations can still apply to all architectures, however).
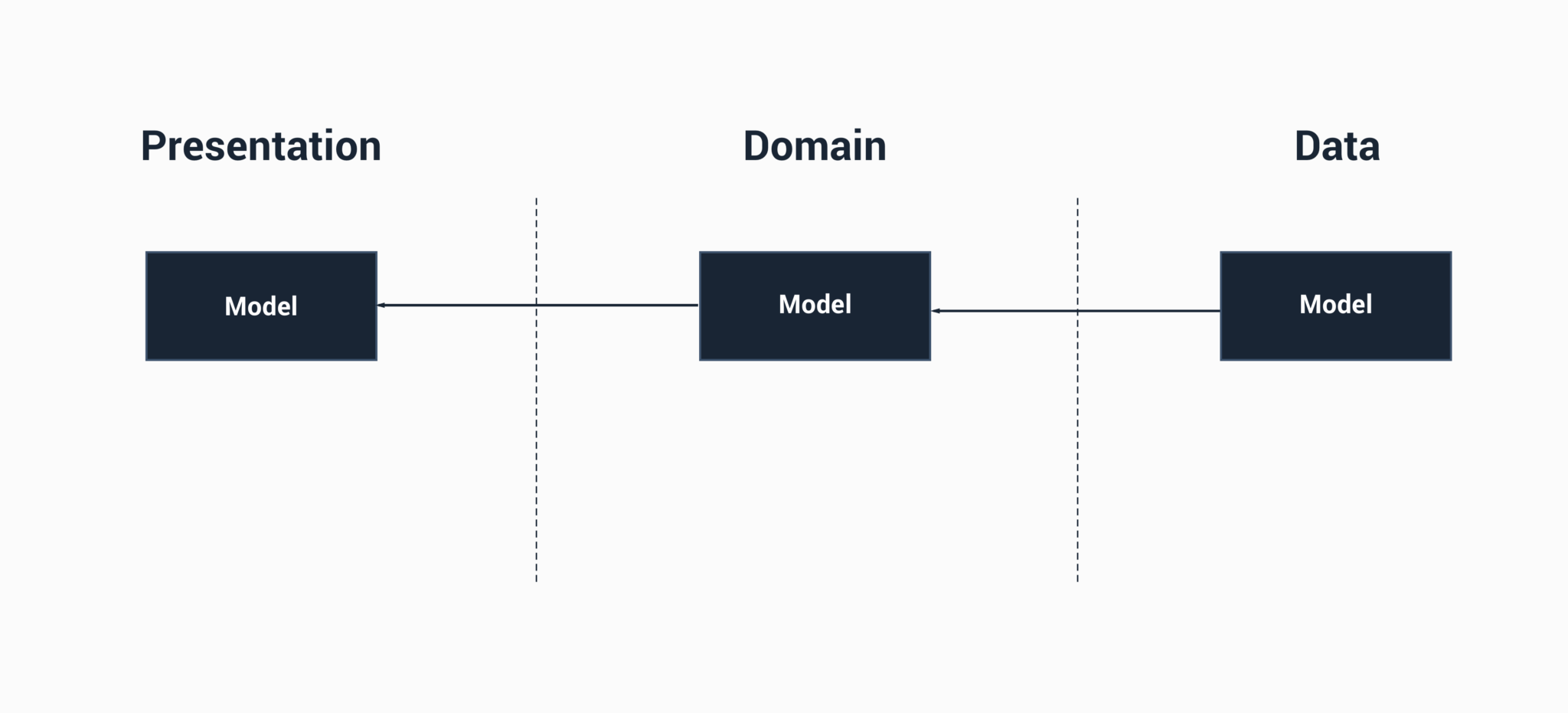
Regardless of whether or not our project is modularised here, we have 3 clear lines of responsibility in our project. Each of these models is its own layers representation of data – it’s quite similar to what we had before except we have a separate model representation now for the domain layer of our application – these are our core business rules, so represent the pure business object of the application. But then what about the data layer, we have one model representation – what about the Cache model and API model representation that we talked about? Hmm, let’s fix that:
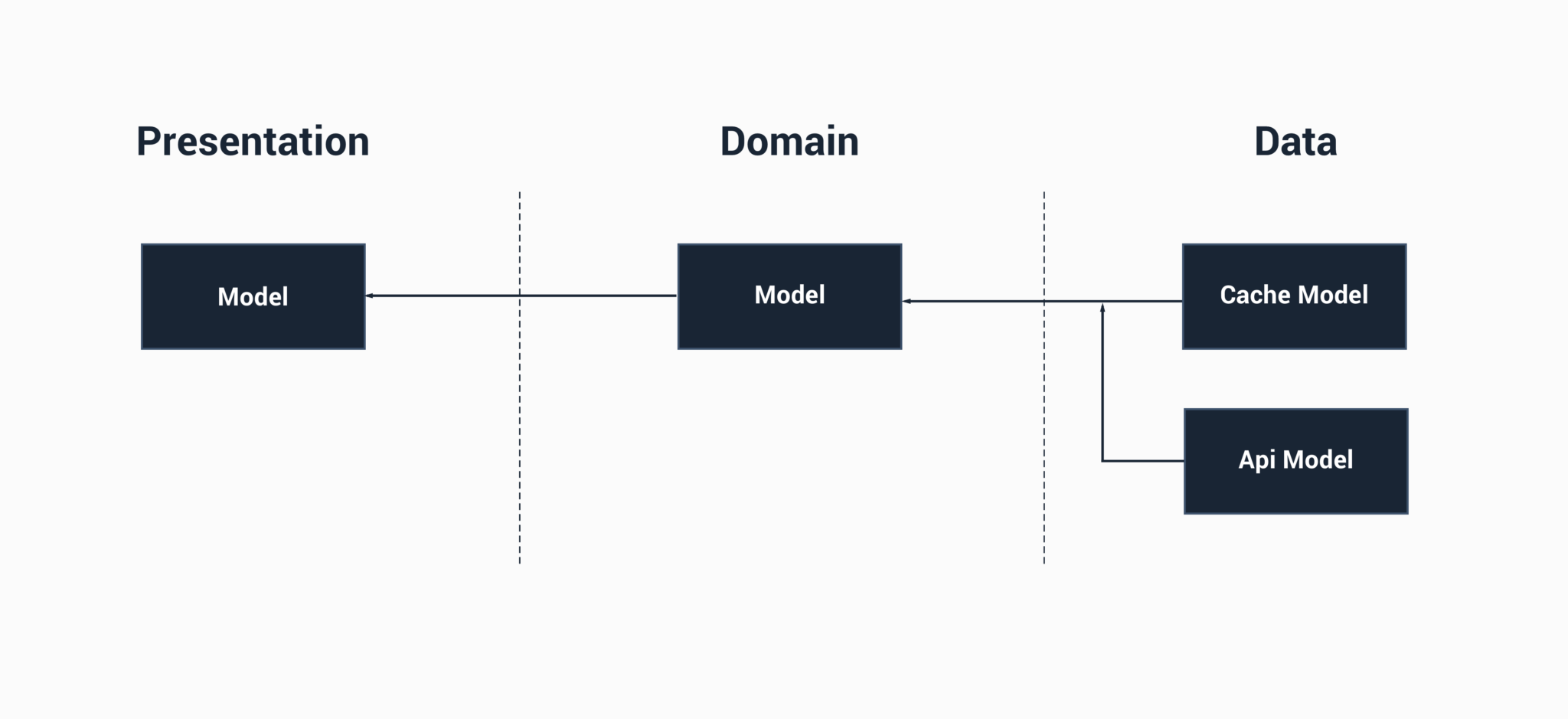
OK cool, so now we have a cache and API model in our data layer and these now both map to the model in the Domain layer. Now, in this case, our Data layer has knowledge of both the Cache model and the API model, this isn’t necessarily an issue as we can easily map to the Domain layer model representation from within the Data model. However, I have seen in some projects, this happen:
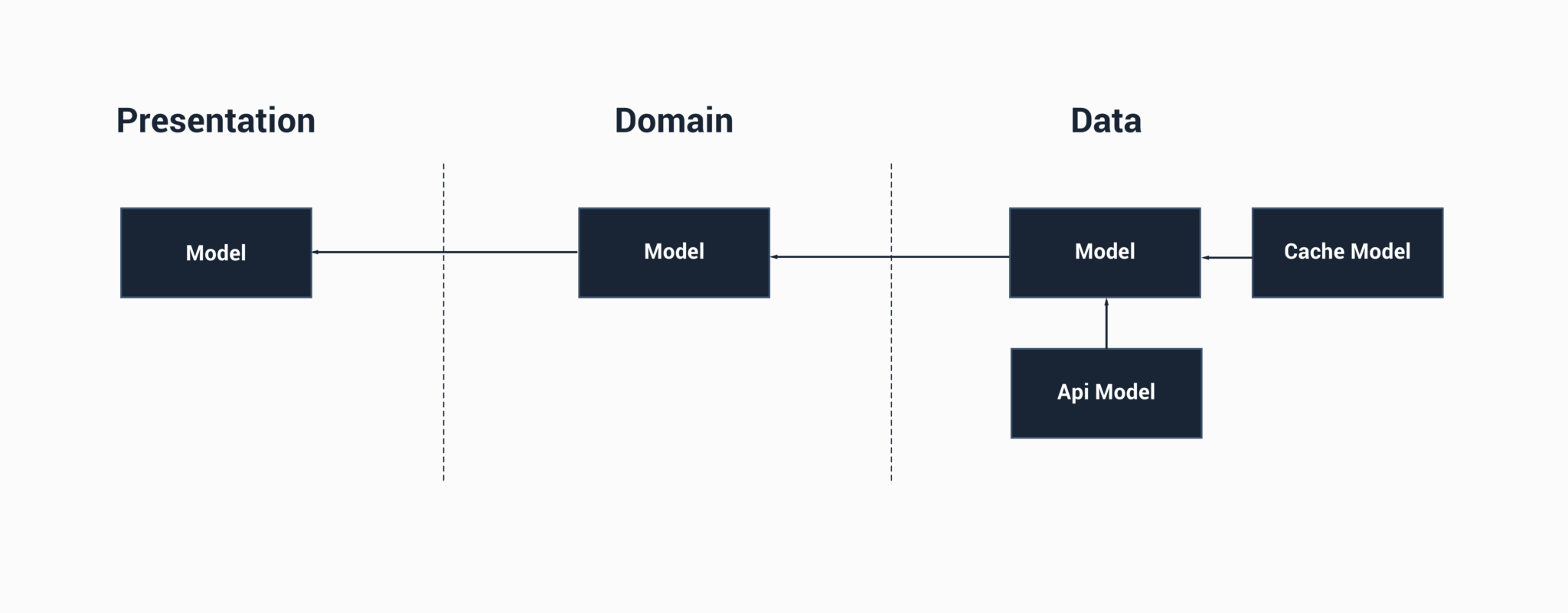
The data layer now has it’s own representation of data, the API and cache model simply map to this. Now, I’m not sure about this personally. I feel like it adds a little more complexity than is needed as we now have 3 models in our data layer – we’re like at this halfway point of creating a line of responsibility, but our data layer is still tightly coupled with these different concepts. If we really wanted this clear line of separation we would go ahead and do something like:
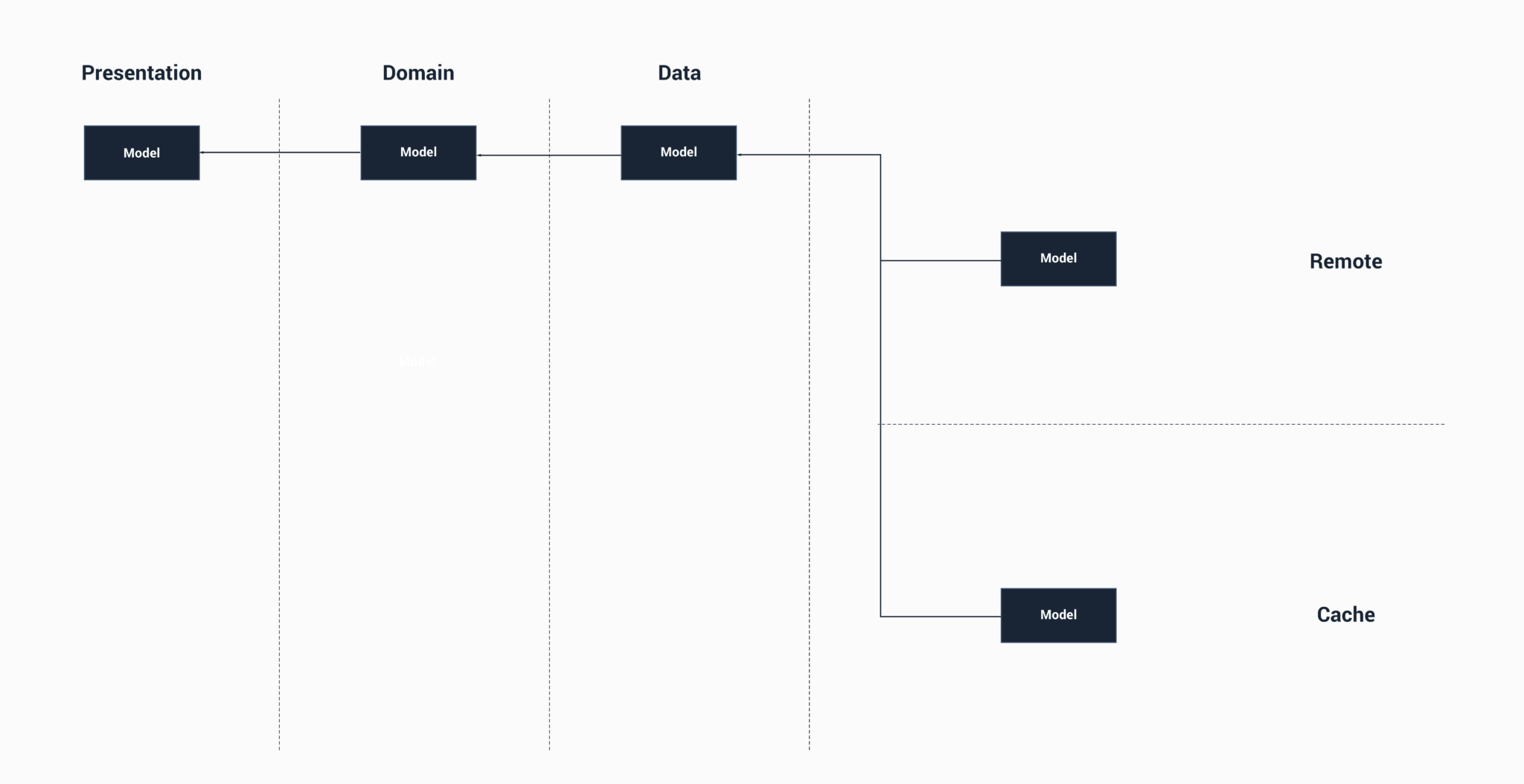
At least with this approach, we now have the separation of responsibilities that our data layer was hinting at, but not quite reaching. Now again, with this approach, you then add that extra layer of abstraction from the data layer, but in that way, you then have a data layer that is not knowledgeable about where the data is coming from and is independent of implementations. But as in a lot of cases, this extra layer of abstraction can add more complexity – so it only makes sense where it is required (for example, larger applications where this data layer could become bloated or in other cases where you feel this abstraction is necessary).
But, in this case, we can end up with what I now call Mapper-Syndrome – if our application has 5 or so layers we are going to end up with a lot of mappers. So whilst this separation of concerns does add a bunch of benefits, it’s also clear that it comes with some downsides. Let’s take a quick look at some of these:
Layer-specific models keep clean of bloat
As we’ve mentioned already in this post, having separate models for the different layers of your application helps to keep models clear of unnecessary bloat. For example, having a model representation that contains only UI specific logic means that this is all it will ever contain – it will never have caching logic or API model annotations. The same applies for Cache models and API models, each model will be easier to understand for developers working in the code, as the classes will be more focused and not overhauled by bloat. As mentioned earlier, the Profile class in our app had been a single model representation (since the app was made) – this object was extremely bloated and difficult understand what data was coming from where, and where that data was being used. Layer-specific models can easily help you to overcome this.
Less likely to break model logic
I’m sure we’ve all been in a situation where we’ve changed something in one place of an app and it’s broken something somewhere else. Having fewer dependencies on a single model representation reduces the chances of breaking stuff during changes (well, your tests should be catching that ?) and it means that you can make changes to a layer without worrying about those changes affecting other parts of your application. As a result, this makes your models and your application much easier to maintain and extend upon.
Layers become more independent
If you’re separating your application into layers (whether you’re using modularisation or not) having models per layer gives each of your layers more independence from other layers. This means that if you need to switch out layers then you can easily do so without worrying about breaking a required dependency and also in terms of modularisation, if you’ve gone to all the effort to create a clear line of separation, to begin with, it doesn’t make sense to then tightly couple these layers by a shared model instance.
Reduced chances of conflicts throughout the team
Another benefit of having these different model instances (and building on that clear line of separation) means that the independence of modules allows work to become contained, meaning that there is a much greater chance of conflicting work. For example, if engineers can easily work on different layers of an application feature without conflicting their work – or even work on completely different features without the worry that some shared model instance across an application is going to conflict their work in some way.
Easier to encourage smaller, more focused tasks
And building on from the above, large pull requests coming from tasks make it hard to perform code reviews when there is so much going on in a pull request. Because a specific layer of the application will have its own specific model, you can create a layer for a feature or refactor without the need to touch other layers, as you have all you need inside of the current layer you are working inside of. This makes the task at hand smaller and more focused.
On the Android team here we are trying to enforce a maximum of 600 line changes per pull request – this makes the review process much easier and the code quality is likely to be higher, as focusing on checking the pull request becomes much easier.
Mapping models can be tedious
So this is one of the downsides of mapping models – it can feel tedious having to map between every single layer of your application. The mapping between a UI, Cache and API model feels reasonable at first – but what if your application has 20 different data models, what if all of these 20 models then have nested models – what do you do in these cases? The situation gets even more tedious when you have more layers in your application also. For example, in clean architecture you could have say between 3 to 6 layers, do you map every single model here? And if you don’t, you kind of defeat the point of the separation of concerns, which makes you feel like you should be mapping models here to reap all the benefits.
This puts you in a bit of a tricky position, so you either end up mapping all models or you end up partially mapping models across your application. Either way, you are going to be required to make a trade-off. The mapping between models can be made more manageable by a well-organised package structure – I am yet to discover a tool or process that makes this flow more simple.
Performance overheads
I’ve not been able to carry out any performance analysis on the mapping of data models (I would love to see any information if anyone has any), but there have been discussions about model mapping having an impact on the performance of applications. I’m not entirely sure if this is a notable impact, especially if you are mapping small models between 2 layers. But I imagine this issue could arise when mapping large and complex objects between multiple layers of an application.
Sometimes, you don’t need a model instance
In some cases, you won’t even need to map a model between layers. For example, let’s say you have a model returned by an API that has a nested error object which contains an error message to be used in the UI. Rather than pass this along 3 – 5 layers to reach your presentation, utilise the tools your application is using. For example, if you’re using RxJava, throw an error in the stream of data using the error message – this way the error will be received via the subscription in the corresponding class. You could even use Completables in places where necessary – these solutions may be different for your implementations, but approaches like this could help you avoid mapping a model between different layers when you don’t really need to.
It all depends on the team and project structure
At the end of the day, it all comes down to what works best for your team and how you choose to structure your project (or even how you can work with how it is already structured). I feel this generally applies to a lot of practices in software development, if it makes sense and works well for your team then that is important – but be sure to bear in mind a solution that will work well for future developers who may be working on the project.
Conclusion
I hope from this article you’ve been able to see how mapping models between layers can make sense in a lot of situations and the benefits that it can bring. But at the same time, also helped you to think that maybe sometimes it might not be entirely necessary to do so, depending on the circumstances. I’d love to hear about how you’re mapping models in your applications and the decisions behind your approach ?
Try Buffer for free
190,000+ creators, small businesses, and marketers use Buffer to grow their audiences every month.


