

A while ago we published this article on how we were trying to tidy up the Android project for the Buffer for Android app: /2016/09/26/android-rethinking-package-structure/.
However, our project is now moving towards a modularised approach – so our package structure is changing (but also staying slightly the same). We wanted to keep the package-by-feature approach in place so we can continue to benefit from its advantages such as it being super easy to navigate around the project.
We recently released two boilerplate projects for clean architecture and during the creation of these, it was a great chance to experiment with how we would package our projects from now on when using a modularised approach. The project structure for the modules looks like this:
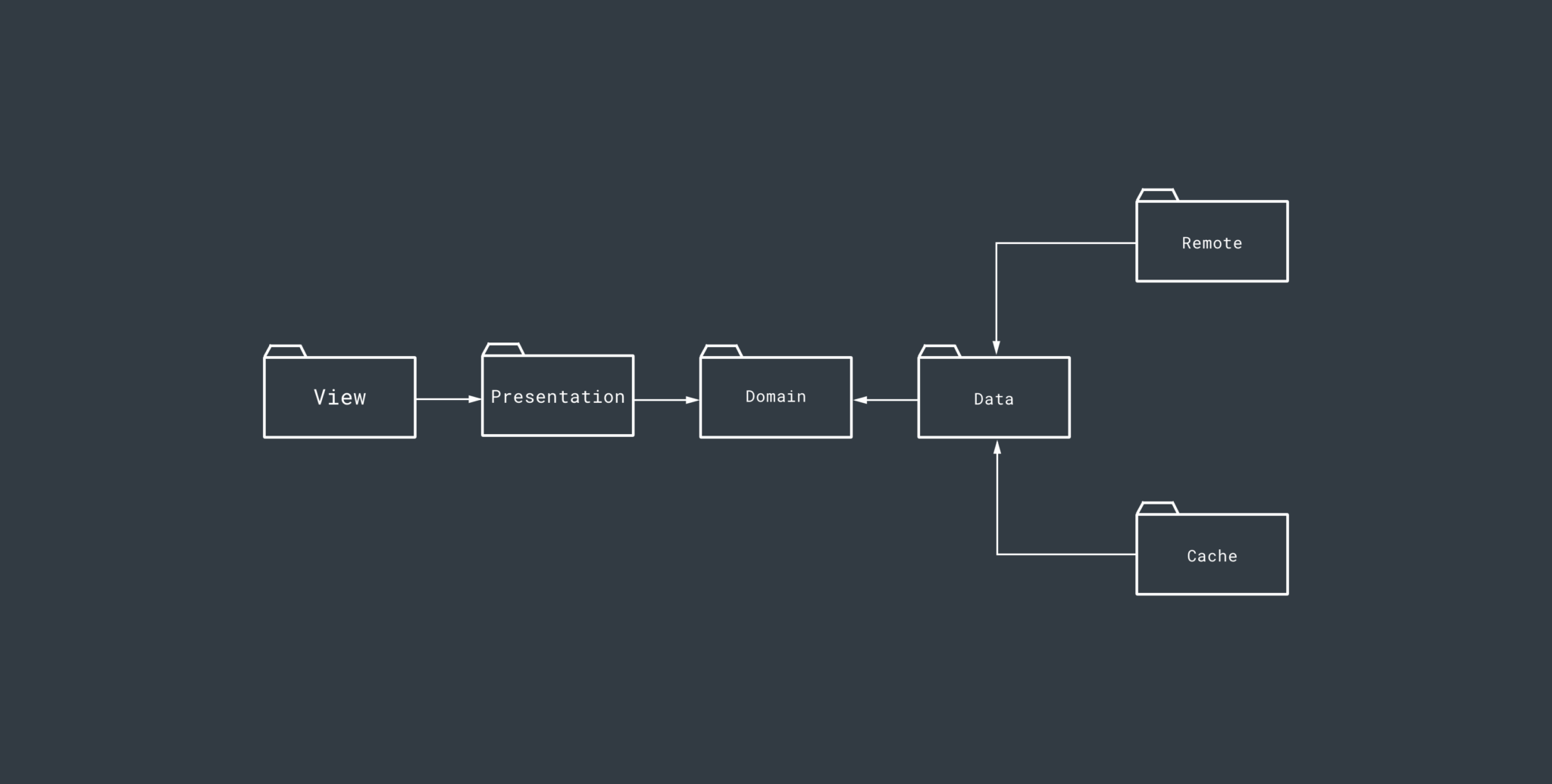
Whilst this approach has received positive responses in the community, I received a couple of emails direct messages asking about how to package by feature when using clean architecture (or in fact, any approach that involves modularising your project) when it comes to Android apps. If you haven’t seen these boilerplates yet, then you can do so here:
https://github.com/bufferapp/android-clean-architecture-boilerplate
https://github.com/bufferapp/clean-architecture-components-boilerplate
Because of these questions, I felt it would be the right thing to do to write a short piece on how we can still package our projects by feature even when modularising our applications. And you know what the great thing is? It’s not even a complicated process or even that different from how we approach package-by-feature in single module projects. So with that in mind, let’s dive in ?
Note: This article will be packaging our features with the concept of Clean Architecture in mind, but the approach can still be applied to other modularised approaches.
Domain Layer
The Domain Layer is the central point of our modularised project – it houses our business objects and contains the Use Case classes used to interact with these from other layers. As well as these, it also defines the interface used by the Use Cases to retrieve these from an out layer which is to implement it. The Domain layer in a current project we are working on looks something like this (some features have been removed from the structure for simplicities sake):
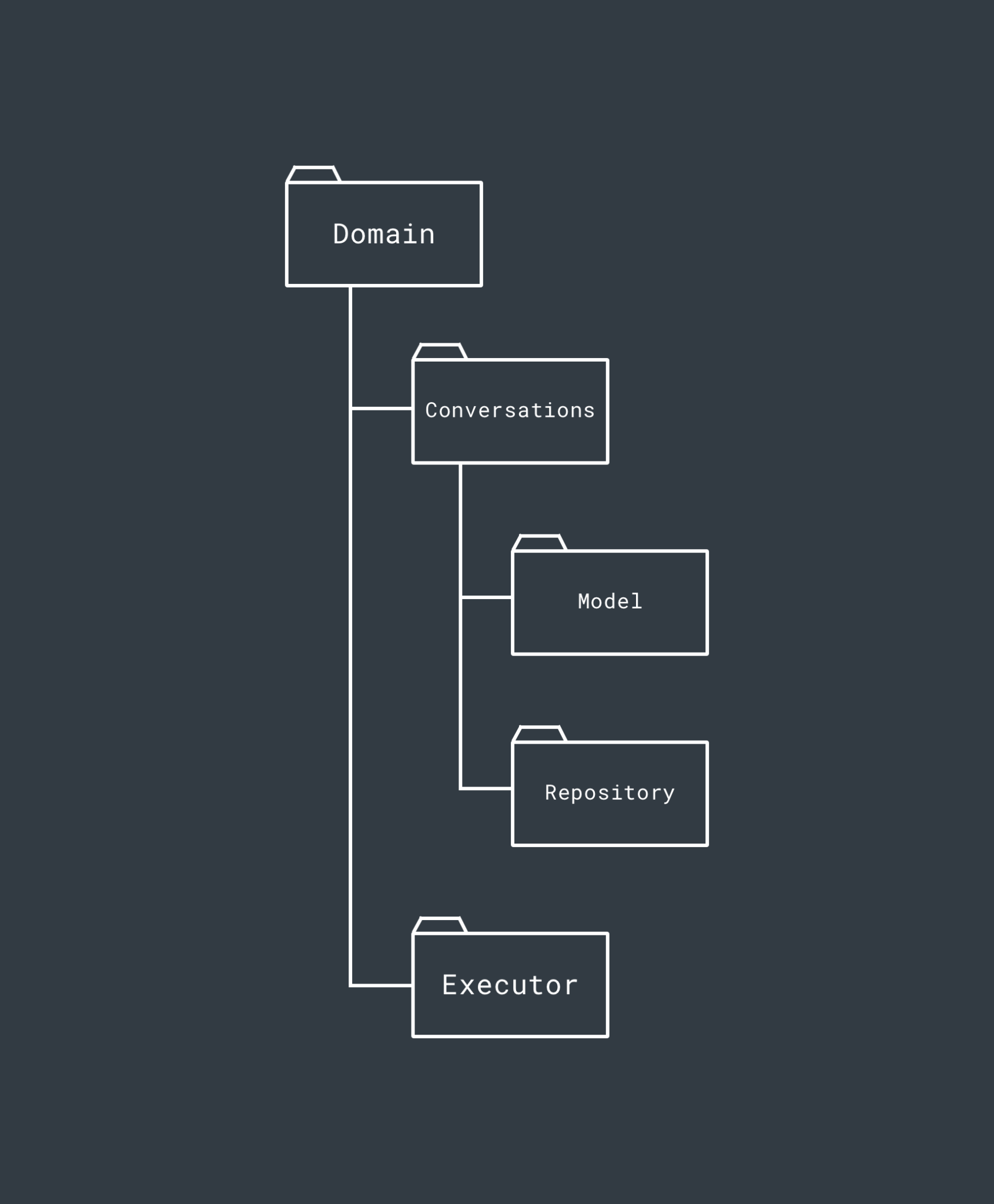
Within the Domain layer, the intention is to package everything by the feature that it belongs to. Here, Conversations is a feature of our application (this may be the retrieving of all conversations or maybe even a single one). If we were to have other features here, then they would be in their own feature package, for example; Message, Settings, Account would all be appropriate kinds of features to package under. Now whenever I need to tweak something within the Domain layer of the project, I can jump straight into the feature that I am looking to amend.
Within the Conversations feature, we then go ahead and package classes accordingly. So within this package, we have:
- A Model package to contain all of the model classes that are related to conversations
- A Repository package which contains the interface our Conversation Use Case classes use to manage operations related to the models in this package (the Data layer will provide an implementation of this interface)
Within the Conversation package, we will also have the different Use Cases which are related to Conversation operations. If you only have one or two use cases, these don’t necessarily need to live within a package – but if your Use Cases grow then it would make sense to package these up appropriately.
Outside of these feature packages we then have the Executor package. This contains abstractions for the management of Threading within our application. You may not have this so this package would be redundant if so.
Why is packaging the Domain layer by feature necessary? Well, imagine if we had 8 different features that weren’t packaged by feature… having an Interactor directory that contained the Use Case classes for 8 different features would get quite difficult to navigate over time. The same applies to mixing all of the Models or Repository interfaces into generic Model / Repository packages – the time taking for navigational actions adds up over time, it’s much easier on the mind to keep these in an organised fashion.
Data Layer
The Data Layer is the central point of access for Data within our modularised project – it houses the implementation for the data access interface defined in the Domain layer, as well as the repository interfaces to be used by the data source implementations for outer layers. The Data layer in a current project we are working on looks something like this (some features have been removed from the structure for simplicities sake):
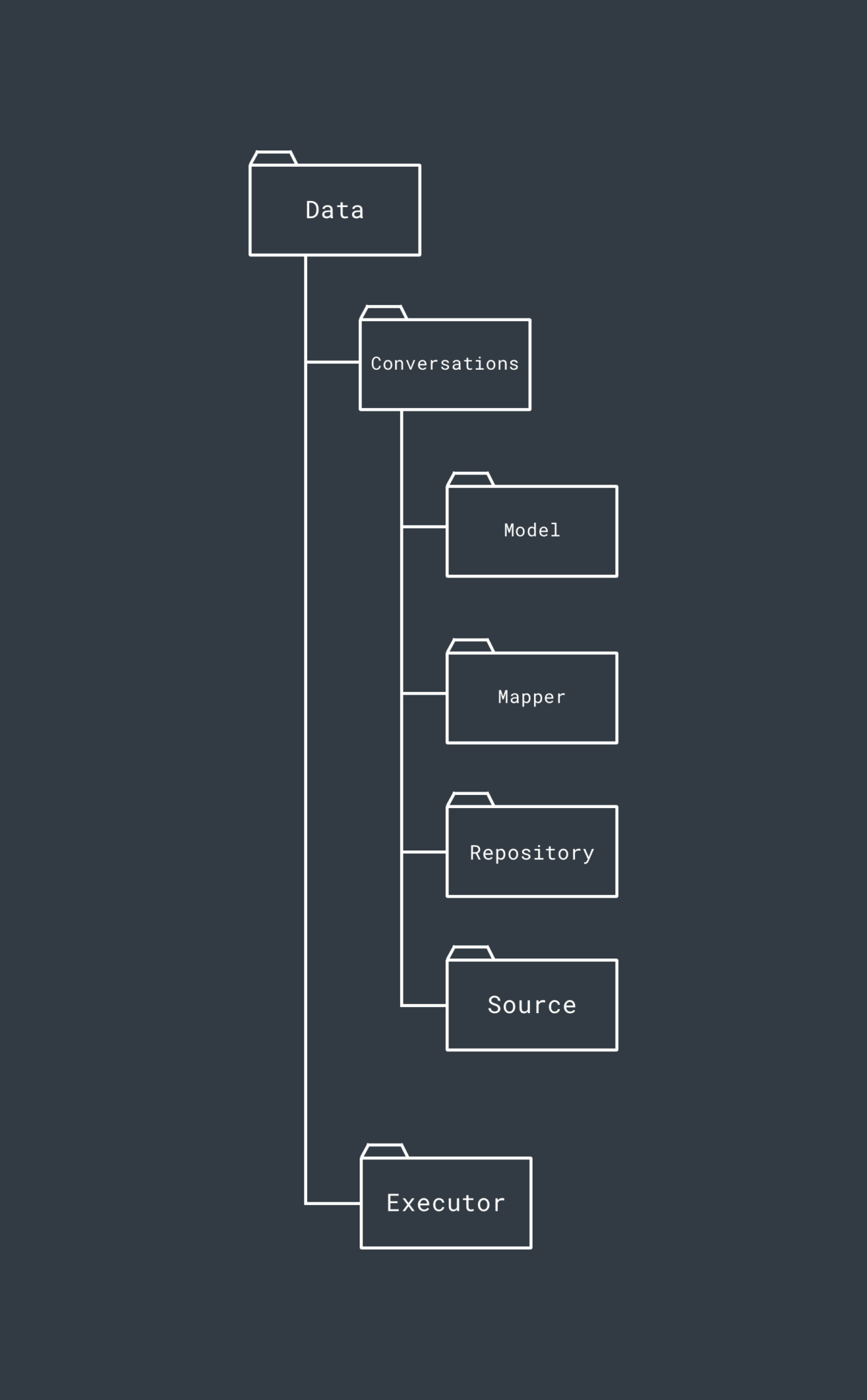
Within the Data layer, the intention is again to package everything by the feature that it belongs to. Here, we see the Conversations feature again which has the same purpose of packaging up everything conversation related within the Data layer. Again, if I need to amend something within the Data layer it is incredibly easy to find what I need to change – no hunting around for that file!
Within the Conversations feature, we then go ahead and package classes accordingly. So within this package of the Data layer we have:
- A Model package to contain all of the model classes that are related to conversations. These are this layers representation of the Models
- A Mapper package which contains the mappers used to map this layers Model implementations to and from the Model defined found with the Domain layer
- A Repository package which contains the interfaces for outer data layers (such as Cache and Remote) to implement. This allows us to enforce the operations that are required and abstract the implementation. it will also contain a Data Store interface which is used to enforce the operations to be implemented by this layers local/remote data store
- A Source package which contains the implementation for the data store interfaces for the data store interface defined within the Repository package. This approach allows us to define the same operations to be implemented by all sources from a single interface. The package will also contain a Factory class to create the desired Data Store class.
Within the Conversation package, we will also have a Repository implementation for the interface which we defined within the Domain layer. This is the implementation which will be used during the data operations for our Use Case classes. There will only be one of these per feature package, so it’s not necessary to put it into its own package.
Outside of these feature packages we then have the Executor package. This contains the implementations for the management of Threading defined within the Domain layer. You may not have this so this package would be redundant if so.
Why is packaging the Data layer by feature necessary? Again, imagine if we had 8 different features that weren’t packaged by feature. having a Source directory that contained the Data Store implementations for 8 different features would get quite difficult to navigate over time. The same applies to mixing all of the Models or Mapper classes into generic Model / Repository packages, we want to focus on creating over searching ?
Remote Layer
The Remote Layer contains the implementation for the remote data source within our modularised project – this houses the implementation for the remote data store interface defined in the Data layer. The Remote layer in a current project we are working on looks something like this (some features have been removed from the structure for simplicities sake):
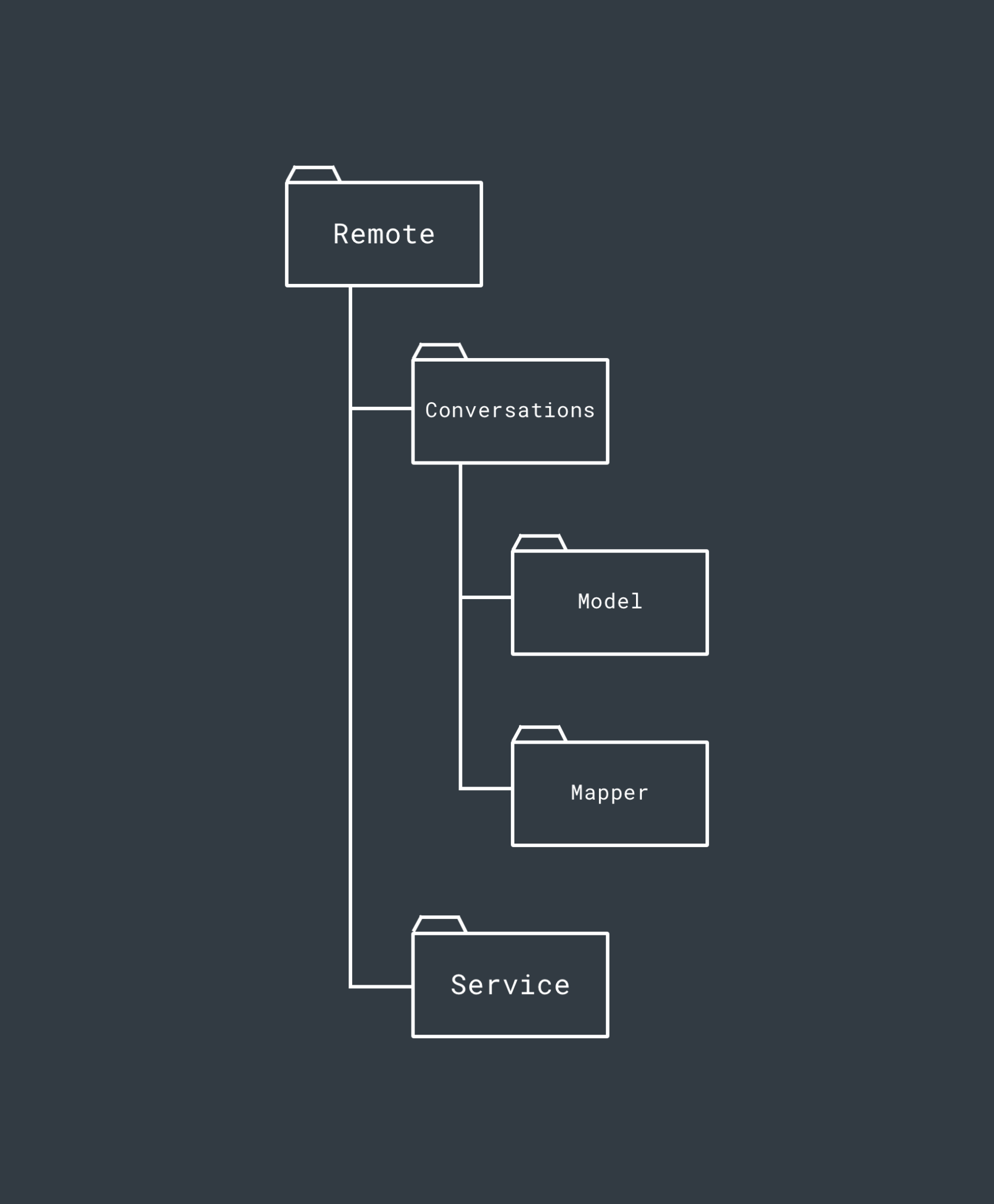
Within the Remote layer, the intention is again to package everything by the feature that it belongs to. Here, we again see the Conversations feature again which has the same purpose of packaging up everything conversation related within the Remote layer.
Within the Conversations feature, we then go ahead and package classes accordingly. So within this package of the Remote layer we have:
- A Model package to contain all of the model classes that are related to conversations. These are this layers representation of the Models
- A Mapper package which contains the mappers used to map this layers Model implementations to the Model defined found with the Data layer
Within the Conversation package, we will also have a Repository implementation for the interface which we defined within the Data layer. This is the implementation which will be used to provide the operations required for fetching the data from the remote source. There will only be one of these per feature package, so it’s not necessary to put it into its own package.
Outside of these feature packages we then have the Service package. This contains the Retrofit interface we use to carry out our network operations, as well as a factory class used for creating an instance of our API service.
Why is packaging the Remote layer by feature necessary? At this point, I am hoping that I don’t need to back up my argument again – but I hope by now you can see the benefits of this!
Cache Layer
The Cache Layer contains the implementation for the local data source within our modularised project – this houses the implementation for the cache data store interface defined in the Data layer. The Cache layer in a current project we are working on looks something like this (some features have been removed from the structure for simplicities sake):
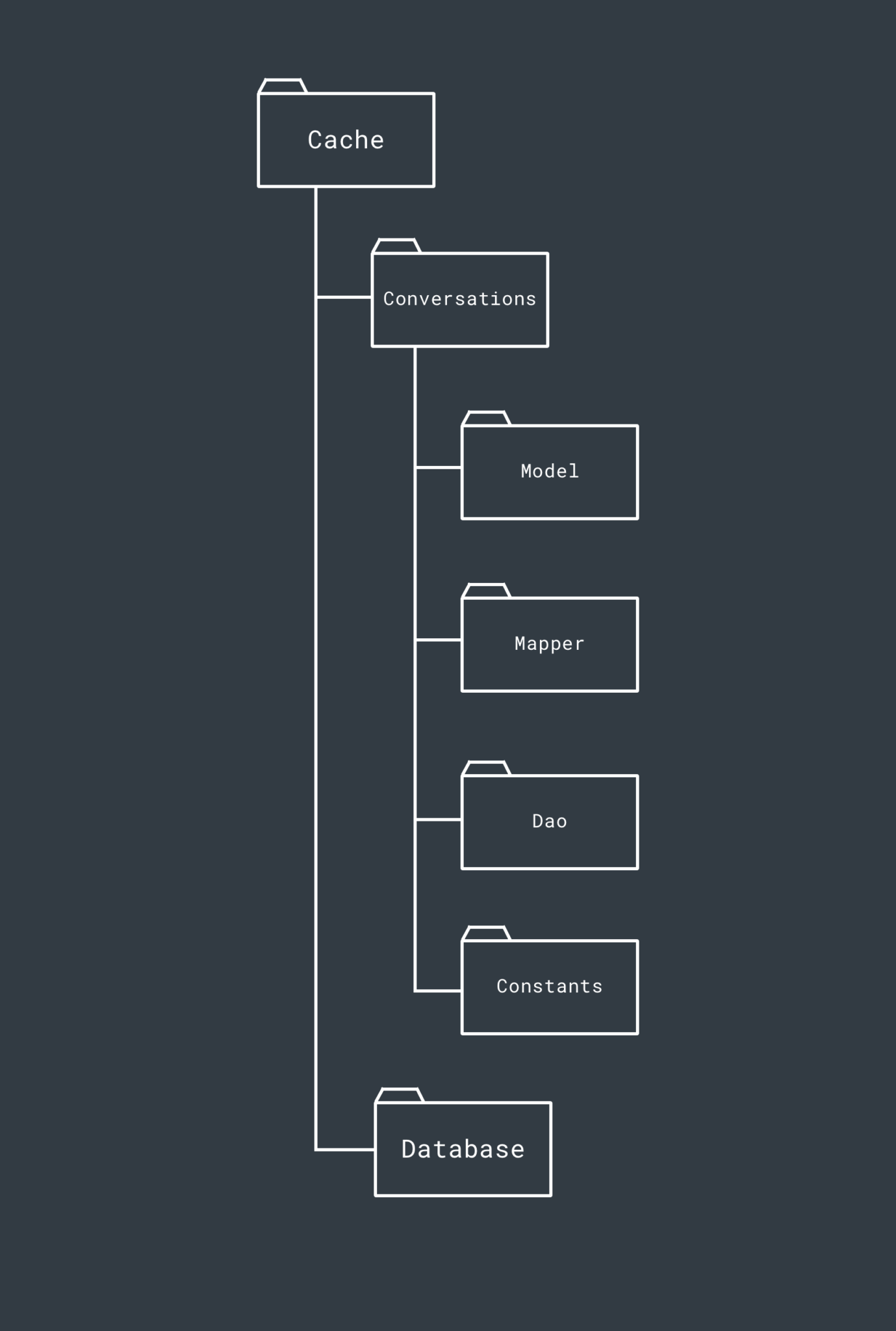
Within the Cache layer, the intention is again to package everything by the feature that it belongs to. Here, we again see the Conversations feature again which has the same purpose of packaging up everything conversation related within the Cache layer.
Within the Conversations feature, we then go ahead and package classes accordingly. So within this package of the Cache layer we have:
- A Model package to contain all of the model classes that are related to conversations. These are this layers representation of the Models
- A Mapper package which contains the mappers used to map this layers Model implementations to the Model defined found with the Data layer.
- A Dao package which contains the Room DAO implementations for the storing/retrieval of Conversation data
- A Constants package which will contain a constants file for conversation queries and column names etc
Within the Conversation package, we will also have a Repository implementation for the interface which we defined within the Data layer. This is the implementation which will be used to provide the operations required for fetching the data from the local source. There will only be one of these per feature package, so it’s not necessary to put it into its own package.
Outside of these feature packages we then have the Database package. This contains the Room database implementation used for storing our local data and any other related database files (such as migrations)
Presentation Layer
Now if we hop back over to the other side of our Domain layer we can take a look at the structure of the Presentation layer. The Presentation Layer contains the presentation logic used within our modularised project – this houses the implementation for the classes which will use the Use Cases from our Domain layer to retrieve and store data (this may be either Presenters or View Models). The Presentation layer in a current project we are working on looks something like this (some features have been removed from the structure for simplicities sake):
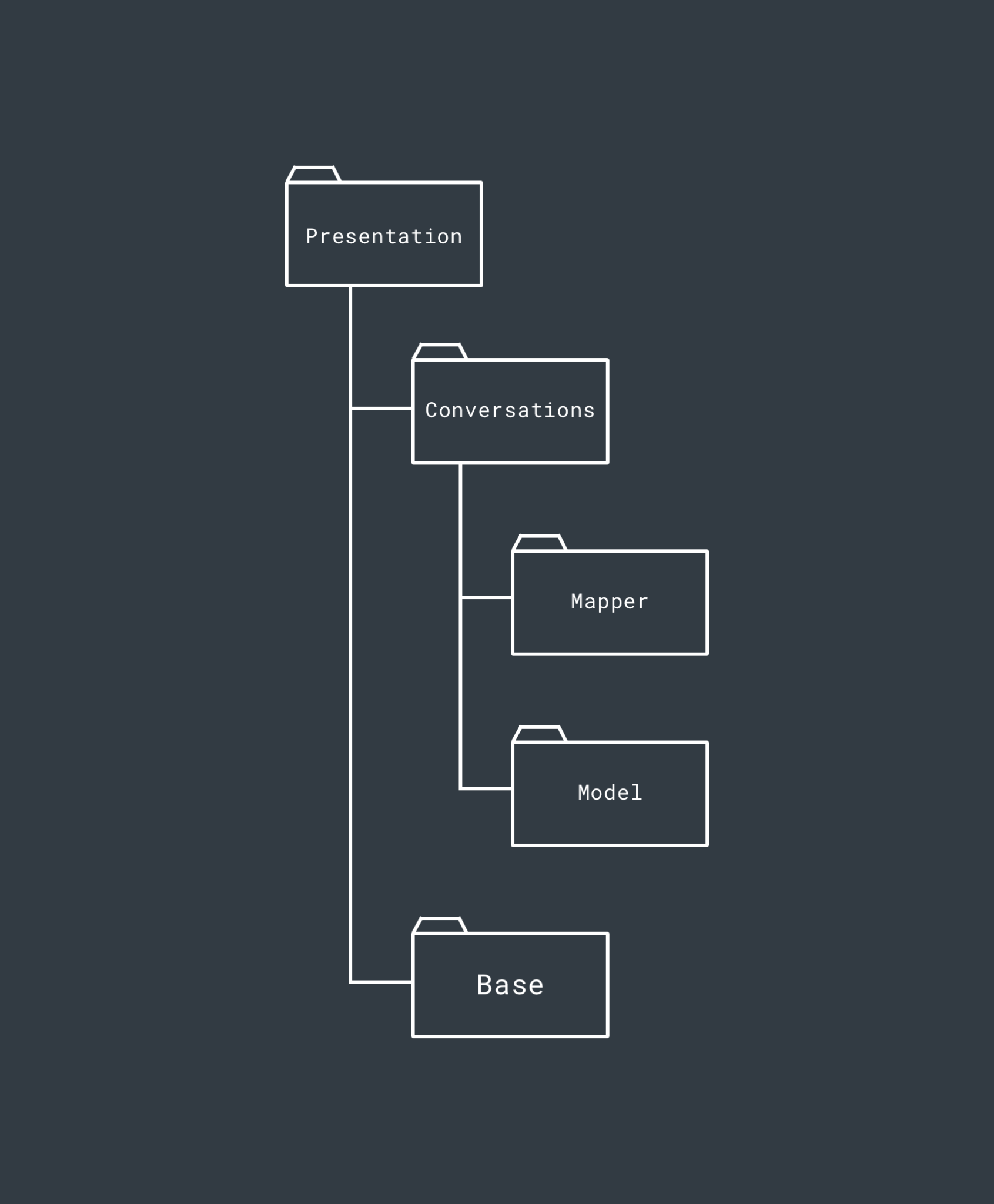
Within the Presentation layer, the intention is again to package everything by the feature that it belongs to. Here, we again see the Conversations feature again which has the same purpose of packaging up everything conversation related within the Presentation layer.
Within the Conversations feature, we then go ahead and package classes accordingly. So within this package of the Presentation layer we have:
- A Model package to contain all of the model classes that are related to conversations. These are this layers representation of the Models
- A Mapper package which contains the mappers used to map this layers Model implementations to the Model defined found with the Domain layer.
Within the Conversation package, we will also have either our Presenter or View Model implementations. This is the implementation which will be used to communicate with the Domain layer and also pass the required data through to the View layer (and handle the presentation if using Presenters). There will only be one of these per feature package, so it’s not necessary to put it into its own package.
Outside of these feature packages we then have the Base package. This package will contain any Base classes used to enforce behaviour between implementations (such as a BasePresenter or BaseViewModel etc).
View Layer
The View Layer contains the views used within our modularised project – this houses the activities/fragments/widgets which will use the classes from our Presentation layer to retrieve handle data (and presentation if using presenters). The Presentation layer in a current project we are working on looks something like this (some features have been removed from the structure for simplicities sake):
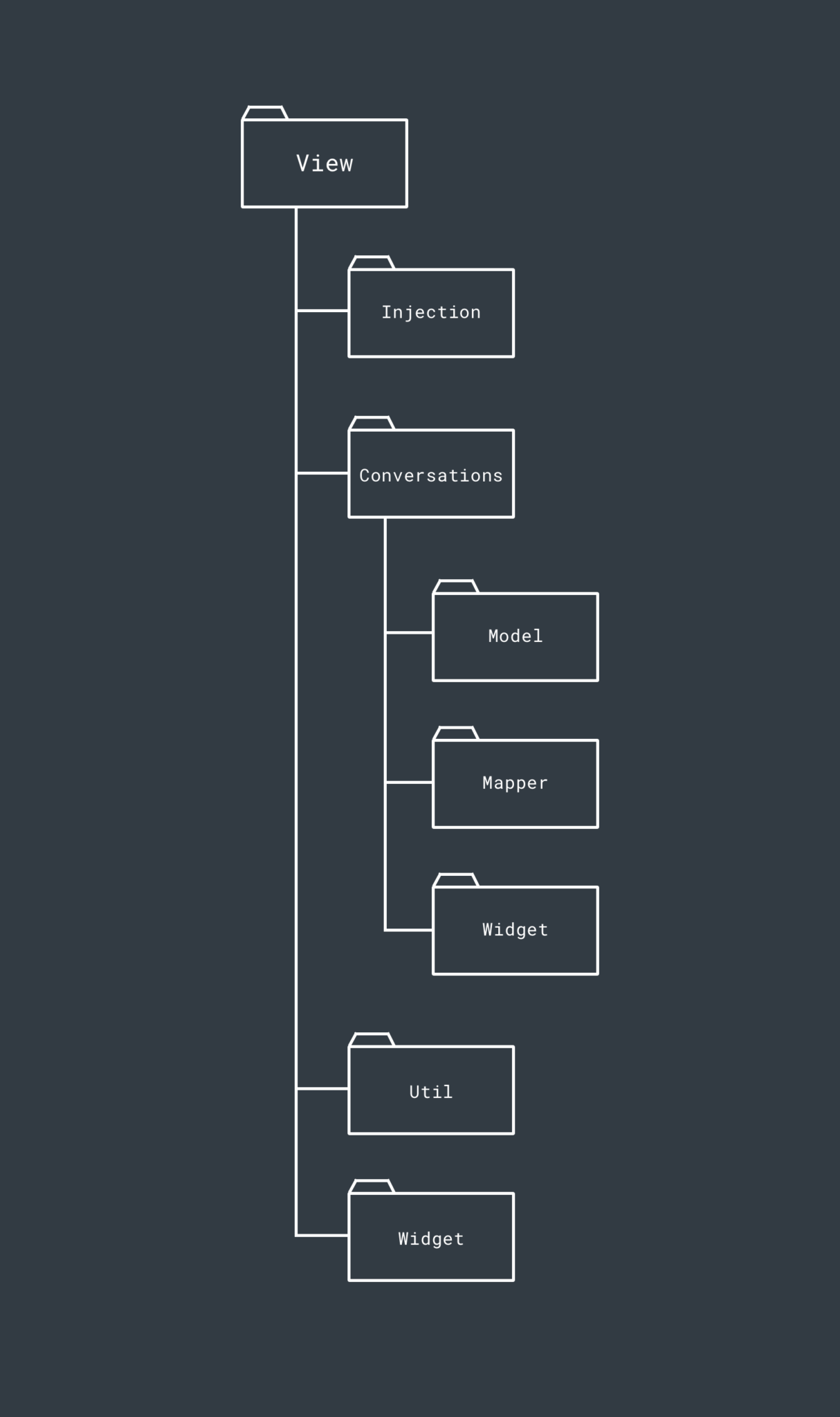
Within the View layer, the intention is again to package everything by the feature that it belongs to. Here, we again see the Conversations feature again which has the same purpose of packaging up everything conversation related within the Presentation layer.Within the Conversations feature, we then go ahead and package classes accordingly. So within this package of the View layer we have:
- A Model package to contain all of the model classes that are related to conversations. These are this layers representation of the Models – personally, we do not map again from the presentation layer as it is not entirely necessary. This is down to personal preference though
- A Mapper package which contains the mappers used to map this layers Model implementations to the Model defined found with the Presentation layer. This will only be necessary if you map to a model that is specific to this layer
- A Widget package which houses widgets specific to this feature and not used elsewhere
Within the Conversation package, we will also have our View implementations (such as an activity or a fragment). This will then make use of the corresponding class from the presentation layer. There will only be one (or two if using an activity-fragment setup) of these per feature package, so it’s not necessary to put it into its own package
Outside of these feature packages we then have the Util and Widget packages. These packages will contain any utility classes and widgets which are used by multiple classes through the View layer. You’ll also notice the Injection package which houses our Dependency Injection configuration – we currently bundle this into our View module, however you can separate this out if you feel that it is necessary.
Conclusion
Whether you’re using the same setup, a similar setup or you’re not using a modularised approach yet – I hope that from this post you can see the benefits from packaging by feature regardless of your project structure. Personally, I find the two concepts go hand-in-hand – modularised projects help to create a clear separation of concerns (which is important whether using clean architecture or not), they allow for a clear focus and for you to carry out smaller implementation tasks at a time. Package by feature compliments this separation of concerns even further by creating a clear and easy to navigate structure within each module.
We’d love to hear any thoughts or questions you may have on this and we’re happy to help should you have any questions ?
Try Buffer for free
190,000+ creators, small businesses, and marketers use Buffer to grow their audiences every month.


