

At Buffer, we’ve been working on a better admin dashboard for our customer advocacy team. This admin dashboard included a much more powerful search functionality. Nearing the end of the project’s timeline, we’ve been prompted with the replacement of managed Elasticsearch on AWS with managed Opensearch. Our project has been built on top of newer versions of the elasticsearch client which suddenly didn’t support Opensearch.
To add more fuel to the fire, OpenSearch clients for the languages we use, did not yet support transparent AWS Sigv4 signatures. AWS Sigv4 signing is a requirement to authenticate to the OpenSearch cluster using AWS credentials.
This meant that the path forward was riddled with one of these options
- Leave our search cluster open to the world without authentication, then it would work with the OpenSearch client. Needless to say, this is a huge NO GO for obvious reasons.
- Refactor our code to send raw HTTP requests and implement the AWS Sigv4 mechanism ourselves on these requests. This is infeasible, and we wouldn’t want to reinvent a client library ourselves!
- Build a plugin/middleware for the client that implements AWS Sigv4 signing. This would work at first, but Buffer is not a big team and with constant service upgrades, this is not something we can reliably maintain.
- Switch our infrastructure to use an elasticsearch cluster hosted on Elastic’s cloud. This entailed a huge amount of effort as we examined Elastic’s Terms of Service, pricing, requirements for a secure networking setup and other time-expensive measures.
It seemed like this project was stuck in it for the long haul! Or was it?
Looking at the situation, here are the constants we can’t feasibly change.
- We can’t use the elasticsearch client anymore.
- Switching to the OpenSearch client would work if the cluster was open and required no authentication.
- We can’t leave the OpenSearch cluster open to the world for obvious reasons.
Wouldn’t it be nice if the OpenSearch cluster was open ONLY to the applications that need it?
If this can be accomplished, then those applications would be able to connect to the cluster without authentication allowing them to use the existing OpenSearch client, but for everything else, the cluster would be unreachable.
With that end goal in mind, we architected the following solution.
Piggybacking off our recent migration from self-managed Kubernetes to Amazon EKS
We recently migrated our computational infrastructure from a self-managed Kubernetes cluster to another cluster that’s managed by Amazon EKS.
With this migration, we exchanged our container networking interface (CNI) from flannel to VPC CNI. This entails that we eliminated the overlay/underlay networks split and that all our pods were now getting VPC routable IP addresses.
This will become more relevant going forward.
Block cluster access from the outside world
We created an OpenSearch cluster in a private VPC (no internet-facing IP addresses). This means the cluster’s IP addresses would not be reachable over the internet but only to internal VPC routable IP addresses.
We added three security groups to the cluster to control which VPC IP addresses are allowed to reach the cluster.
Build automations to control what is allowed to access the cluster
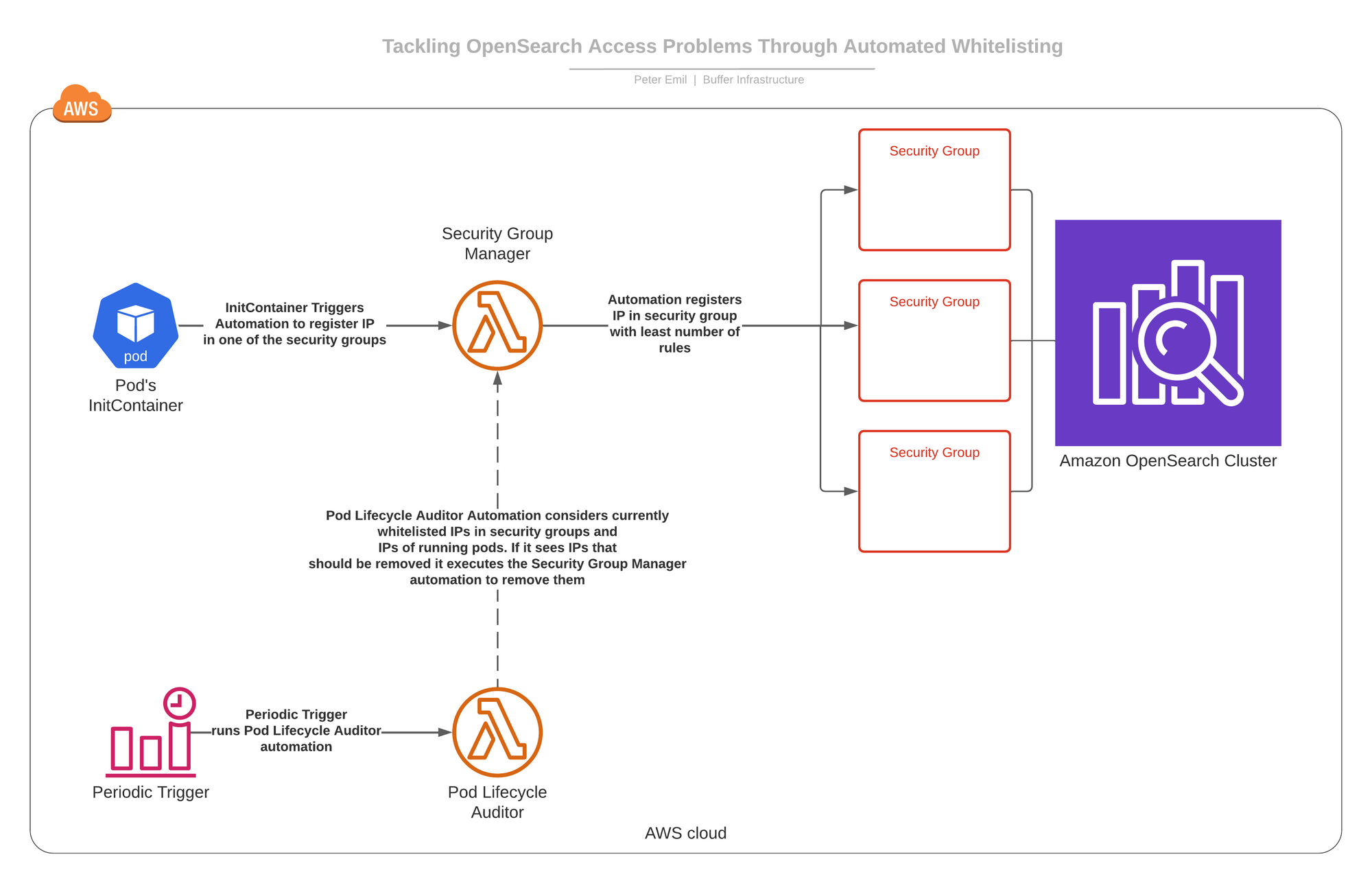
We built two automations running as AWS lambdas.
- Security Group Manager: This automation can execute two processes on-demand.
- -> Add an IP address to one of those three security groups (the one with the least number of rules at the time of addition).
- -> Remove an IP address everywhere it appears in those three security groups.
- Pod Lifecycle Auditor: This automation runs on schedule and we’ll get to what it does in a moment.
How it all connects together
We added an InitContainer to all pods needing access to the OpenSearch cluster that, on-start, will execute the Security Group Manager automation and ask it to add the pod’s IP address to one of the security groups. This allows it to reach the OpenSearch cluster.
In real life, things happen and pods get killed and they get new IP addresses.Therefore, on schedule, the Pod Lifecycle Auditor runs and checks all the whitelisted IP addresses in the three security groups that enable access to cluster. It then checks which IP addresses should not be there and reconciles the security groups by asking the Security Group Manager to remove those IP addresses.
Here is a diagram of how it all connects together
Extra Gotchas
Why did we create three security groups to manage access to the OpenSearch cluster?
Because security groups have a maximum limit of 50 ingress/egress rules. We anticipate that we won’t have more than 70-90 pods at any given time needing access to the cluster. Having three security groups sets the limit at 150 rules which feels like a safe spot for us to start with.
Do I need to host the Opensearch cluster in the same VPC as the EKS cluster?
It depends on your networking setup! If your VPC has private subnets with NAT gateways, then you can host it in any VPC you like. If you don’t have private subnets, you need to host both clusters in the same VPC because VPC CNI by default NATs VPC-external pod traffic to the hosting node’s IP address which invalidates this solution. If you turn off the NAT configuration, then your pods can’t reach the internet which is a bigger problem.
If a pod gets stuck in CrashLoopBackoff state, won’t the huge volume of restarts exhaust the 150 rules limit?
No, because container crashes within a pod get restarted with the same IP address within the same pod. The IP Address isn’t changed.
Aren’t those automations a single-point-of-failure?
Yes they are, which is why it’s important to approach them with an SRE mindset. Adequate monitoring of these automations mixed with rolling deployments is crucial to having reliability here. Ever since these automations were instated, they’ve been very stable and we didn’t get any incidents. However, I sleep easy at night knowing that if one of them breaks for any reason I’ll get notified way before it becomes a noticeable problem.
Conclusion
I acknowledge that this solution isn’t perfect but it was the quickest and easiest solution to implement without requiring continuous maintenance and without delving into the process of on-boarding a new cloud provider.
Over to you
What do you think of the approach we adopted here? Have you encountered similar situations in your organization? Send us a tweet!
Try Buffer for free
200,000+ creators, small businesses, and marketers use Buffer to grow their audiences every month.


