

This post is co-written by David Gasquez.
All the way back in late 2014, we wrote short little blog post about our first big redesign of our data architecture at Buffer.
Back then, the data team consisted of 2 people, handling everything from data infrastructure to analysis and business intelligence (with some part time help from our CTO) within a company of just 25 people. We built out the initial version of our data architecture within 3 weeks, and it served us well for quite a while.
Jump ahead to the present day and our data team has grown to 4 people working closely together with our growth, systems, product, marketing and engineering teams, and the whole Buffer team has grown to 71.
We’ve also amassed a ton more data. By the end of 2014, 270 million social media posts had been crafted through Buffer, since then an additional 875 million was created. We’ve seen a corresponding increase in users and profiles being added, and in total we’ve tracked 2.7 billion user actions to date.
Since the time we’ve shared that blog post, our data architecture has not remained static. We’ve tried out quite a few different technologies and have regularly iterated on our architecture based on feedback and lessons learned.
In the latter part of 2017, we kicked of a new initiative to revamp our core architecture, based on many new requirements, best practices we’ve developed over time that we wanted to apply consistently as well as the desire to do even more with our data than we could before.
As with many other important projects at Buffer, it all started with coming up with a good name. The code name we came up with for the project was BUDA (Buffer’s Unified Data Architecture), and the name has since then stuck.
In this post we would like to introduce BUDA. We’ll talk a bit about the high level principles and components, as well as the considerations that led to their design. We’ll touch on some of the key technological pieces we leveraged and briefly talk about some of the details of what we’ve implemented (with the idea to dive into the details a lot more in future posts).
Motivation
Working with data pipelines can be extremely challenging. We based our legacy architecture in ELT instead of ETL, giving analysts lots of control over data modeling. It served us well during the last few years but with time, it became hard to operate, evolve, and troubleshoot.
Our pipeline started to feel very coupled and changing things wasn’t easy since there wasn’t a standard way to make changes. A lot of time was spent in batch jobs massaging huge loads of events in our data warehouse, which was also being used for analysis. We were limited to SQL transformations and limitations with semi-structured data.
Being aware of the current best practices in this field and after reading a bunch of blog posts, we decided to rebuild our data architecture using modern techniques and tools. We were set to consolidate Buffer Data Architecture under the same patterns.
The new architecture would help us reducing the time we spend managing resources, decreasing the number of bugs in the pipeline and making stuff easy to edit without breaking other stuff.
Buffer Unified Data Architecture
With a new architecture, we could distill all the lessons we learned and best practices in one place, allowing us to use more state of the art ideas in the field of data engineering.
While building BUDA, we aimed to keep a few principles in mind. These are borrowed from greater field of software engineering and helped us to make better decisions. Although not all our pipelines are 100% in line with these principles yet, we’re aiming for it!
- Simplicity: That means that each step in the pipeline is easy to understand, modify, and test. We aim for pure steps (deterministic and idempotent). This way we avoid side effects and we’ll have the same output every time we run them. Do one thing and do it well!
- Reliability: All the errors in the pipeline can be recovered. We can backfill events if something goes wrong. We can scale if we need to handle more data.
- Modularity: Each step can be iterated on independently. Also, each one has an specific purpose. Think of each step as an UNIX tool.
- Consistency: The same conventions and design patterns used consistently. We prefer standards components and methods. It makes easier to understand other parts of the pipeline and reuse components.
- Efficiency: Data flows as real time as possible, and we can scale out to handle load as needed.
- Flexibility: We have the ability to transform, model and annotate data easily to enable power analysis and application of data.
Implementation
As in the rest of computer science problems, there is no silver bullet regarding data pipelines. Based on the trade-offs we’ve encountered, we’ve arrived to our current implementation.
Basically, the pipelines are made of producers and consumers communicating through an event log. Each service takes care of one logical step and sends the processed data back to a stream.
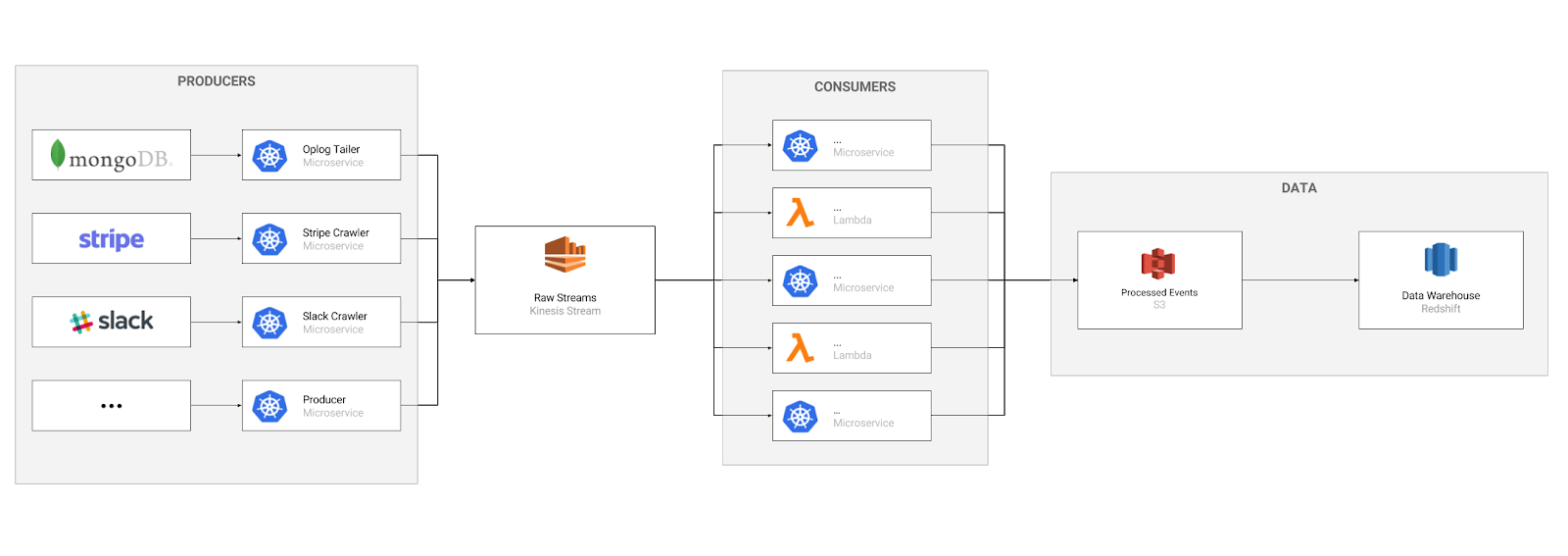
Most of the pipelines starts with what we call Producers. A producer, just as the name suggests, is a source of data, either from events we collect explicitly or pulled in from some external system.
For example, if we want to add Stripe events data to our database to compute Monthly Recurring Revenue we’ll need to have a producer. In this case, a simple Stripe API crawler would do it!
Producers read events from sources and forwards them to the event log. In our case, we’re using AWS Kinesis Streams. Producers will call Kinesis API and place the data in the stream where it’ll live for 24 hours.
Once the data is in the stream, other services can read it. We call components that read from streams Consumers. These consumers are the key pieces of each pipeline. They read the raw data and apply some transformations. Some pipelines needs more complex transformations and we can chain together more consumers placing another Kinesis Stream between them.
Finally, the data is placed on our data storage (S3) in a JSON format and copied over our Data Warehouse (Redshift) using AWS Kinesis Firehose.
After data arrives in Redshift, we can do further modelling of the data using dbt. These models can be queried using SQL directly, but can also be used in Looker which is our general business intelligence, reporting and dashboarding platform
Overall these are the tools and technologies we’re using across the stack:
| Stage | Tools |
|---|---|
| Extract | Python, Docker |
| Load | Python, AWS Firehose |
| Transform | Python, dbt, AWS Lambda |
| Comunications | Protobufs (gRPC), Kinesis |
| Warehouse | Redshift, S3, Athena |
| Explore and Report | Looker |
The Road Ahead
As we said before, BUDA is still a work in progress, there are still legacy parts of our architecture that we haven’t migrated yet, we’re still dealing with new challenges and we’ve learned a lot of things along the way that we can still improve on. We’re excited to continue working towards improving our pipelines in the future and sharing more about the journey.
We’re building BUDA out in the open and have open sourced many of it’s components as well as it’s living documentation, if you wanted to follow along.
In future posts we’ll talk about our two main pipelines we’ve built using BUDA:
- Replicating MongoDB collections in Redshift
- Event tracking with BUDA
Try Buffer for free
200,000+ creators, small businesses, and marketers use Buffer to grow their audiences every month.


