
As Buffer is well into its sixth year of existence, we’ve evolved a lot as an engineering team. When I joined the team in early 2014, we were six engineers, four of whom worked on our main web application and API specifically. We’re now a larger team of 27 engineers, many of us still pushing more code into a single large repo every day. Over time our workflows have evolved to try to keep the development and deployment process light, but with team growth in the last year, we’ve outgrown many of these patterns and practices.
It was time to rip the band-aid off and make a big change.
Here’s the story of how we’re exploring a new service-oriented architecture (SOA) at Buffer to help us stay agile as we scale. Hopefully the process and lessons might be helpful for others who are considering a similar move.
Buffer’s current application
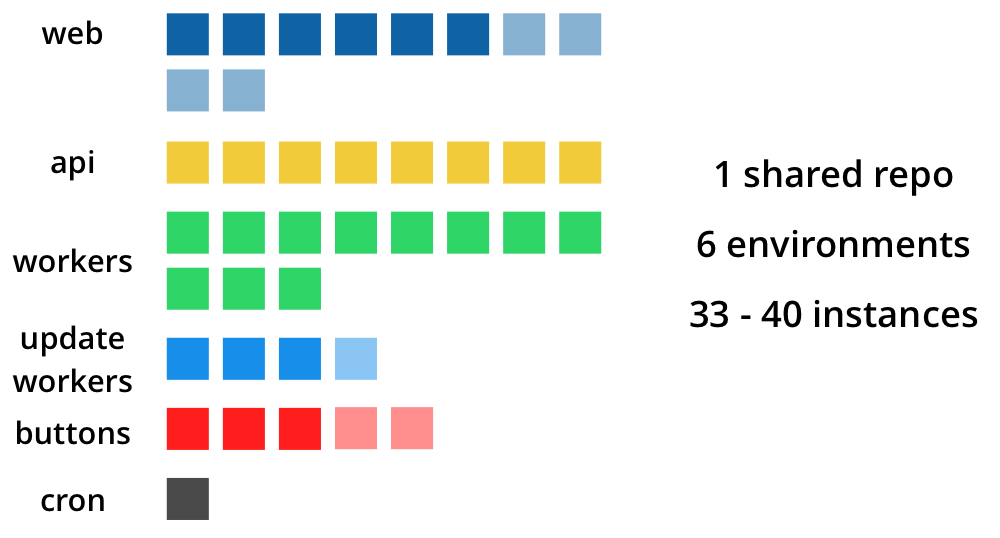
Buffer is primarily made up of a large PHP application and a single-page web app, both housed in a single git repo. Parts of this application run across six environments for the web app, the API, the worker environments that run hundreds of processes, our update workers environment, an environment that powers our Buffer buttons and a server to handle miscellaneous cron jobs.
Coordinating merges and deploys at peak times became a bit of a bottleneck. Tightly coupled parts of the application meant that a fatal error in shared code could bring down a very different part of the application — or worse, the entire application. Growing the number of contributors to web made us quickly realize how fragile things were.
Exploring a different approach: How we decided on SOA
The feeling of fragility was building across the team. In April of this year, I started talking in earnest with Sunil, Buffer’s CTO, about a re-architecture effort. Re-architecture felt like a common challenge many growing engineering organizations face, and we started to see some really amazing solutions out in the wild. We would share articles and videos, and we would brainstorm over Slack the different ways to re-architect Buffer to better scale our development organization.
After a few weeks of asynchronous exchanging of ideas, we had the chance to meet in New York. Together we laid out some ideas on what we needed to do. Our journey toward migrating Buffer to a service oriented architecture was about to start.
Phase I: Choose a platform for micro-services
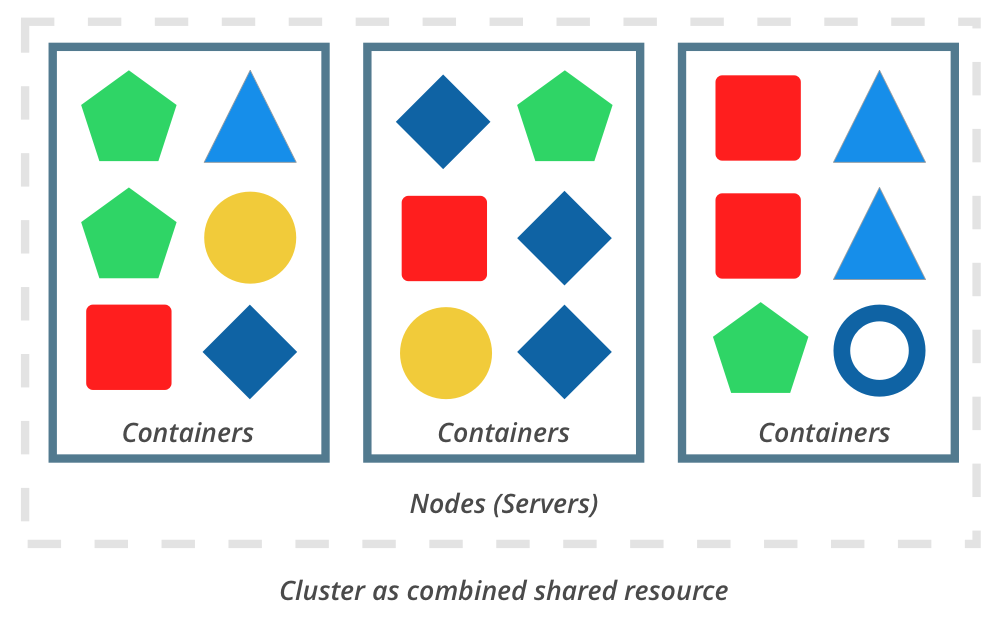
- Cluster orchestration tools like Kubernetes combine the resources of multiple servers to run containers
The first step was to research how Buffer would run micro-services in production. Buffer’s development environment had recently been rebuilt to use Docker containers, so it was a technology that more people on the team were starting to feel comfortable with. With this in mind, we evaluated Kubernetes, Mesosphere, and Amazon’s ECS. Our systems team had past experience with ECS, but there were some disadvantages. We were impressed with Mesosphere DC/OS; however, it didn’t have everything we wanted.
After a few weeks of experimentation, we happily settled on Kubernetes to handle our cluster management and container orchestration needs. There were several factors that led us to choose Kubernetes:
- It’s focus on running containers
- It is cloud-provider-agnostic
- The growing Kubernetes community of developers
- The platform is mature (Started in mid 2014, it hit 1.0 in July 2015)
We hope to share a lot more about this decision in the coming months. For us, Kubernetes had what we needed to go all-in with it as our orchestration platform.
Phase II: Create an implementation plan
During our evaluation period, we began putting together a plan for how to start transitioning our architecture. Instead of having several engineers start building services straight away, we wanted to set some solid precedents early on. Our thinking was that building a few quality services first could act as models for future services, setting a high bar by encouraging good practices and helping prevent future fragmentation in our system.
Borrowing a concept and name from Sam Newman’s Building Microservices, we were out to build out first exemplar. To paraphrase Sam Newman, exemplars are real-world services that implement all your best standards and practices that you’d like to encourage.
A few requirements we decided our exemplar service must have:
- Simple to run and write automated tests with 100% test coverage
- Good documentation
- Simple and quick to access logging
- Automated code linting
- Easy to set up monitoring
- Load testing beyond current production throughput
- Bug tracking
- Dead simple, Slack-based deploys, ex. /deploy <service>
With those goals in mind, we chose our URL metadata scraper functionality to be the first bit of code to extract from our monolith repo. This was an easy service for us to start with as it was stateless, had a clear single purpose, and was developed with a test suite that made it simpler to re-implement. Additionally, this was a core piece of our application so it had to be fast and dependable.
Phase III: Begin slicing up the monolith (Codename: Project ?)
Since we were starting to slice up our monolithic repo, we called this Project Pizza. The goal for Project Pizza was to maximize learning as quickly as possible for hosting our first production service on Kubernetes. We broke requirements into weekly sprints and were able to hit our goals.
Our small systems team ramped up on all things Kubernetes, learning the ropes to ensure we’d be confident our cluster could handle production traffic. They divided ownership of parts of the project. Steven worked on out-logging infrastructure, Adnan focused on cluster management and our deploys, and Eric dug into on reliability monitoring.
After three weeks we started diverting some traffic to our new service. Outside of a few expected minor hiccups and bug fixes, it was capably handling ~250k requests per day on average. This was a major win, but there was still lots left to do.
The team spent the following few weeks working through lots of fun challenges, upgrading to Kubernetes 1.3, and learning how to troubleshoot downtime and issues on our services and cluster. We experimented with different approaches for logging, monitoring, and deploying new images into production. The new services could deploy in under 60 seconds with a single Slack slash command.
Overall, the project was a huge success and the team felt incredibly empowered by the system had in place.
What happens next?
As the initial project wrapped, we were well-positioned to move forward with other services, and we knew we had only just scratched the surface. We saw momentum continue after Project Pizza, and today we’ve now released five production-grade services.
As a team, we’ve ramped up on how to build and deploy services, but there are still many questions. How do we keep the momentum and determine what a service-oriented architecture looks like at Buffer?
At this point, we have started deciding our application’s bounded contexts, and we’re experimenting with new ways that our services will interact with each other. More engineers on the team have started to ramp up on Kubernetes and Docker, and we’re rolling out new services each week. In the near future we’ll work to extract truly core pieces from our application like user authentication and the posting of updates (800k+ a day) into new containerized services.
So far we’ve gotten a taste of the benefits when we decouple services and have lots more to do until all teams at Buffer are able to reap the benefits of end-to-end ownership. It’s been an incredible learning experience for myself and the team so far, and I can’t wait to share more updates and learnings along the way!
Try Buffer for free
200,000+ creators, small businesses, and marketers use Buffer to grow their audiences every month.


